
Enabling Our Server to Handle Concurrent Requests By Implementing a Multithreaded TCP/IP Server

In my previous post, I implemented a bare-bones single-threaded TCP/IP server, helping us understand the intricacies of client-server communication over TCP/IP, in addition to, what goes on inside the server when a client request arrives and the related concepts. In case you haven't read it yet, it's a recommended read before you get on with this post.
This post entails a discussion on the implementation of a multithreaded TCP/IP server that will improve our server's throughput enabling it to concurrently handle a significantly higher number of client requests in a stipulated time.
With that being said, let's get started.
Ways to make our server handle requests concurrently
Our single-threaded server could handle only one request at a time. All the subsequent or concurrent client requests were queued until the primary thread of execution was free to handle the subsequent client request.
In this scenario, when the single thread of execution is busy handling the current client request, the subsequent client requests will experience delays in receiving the response or, worse, connection timeouts.
There are multiple ways to make our server handle the client requests concurrently as opposed to sequentially, increasing its throughput.
1. Multithreading: Spawning a new thread for every client request
In this multithreaded approach, our server will spawn a new thread to handle every client request. Individual threads handling requests of different clients send the responses to respective clients and are terminated, completing their lifecycle.
The downside of this approach is the overhead of thread creation and destruction on every client request. Also, if the number of threads spawned is high, there is additional overhead of thread context switching.
The upside is immediate handling of client requests by a new thread without having to wait on a queue. This decreases the response latency, thus increasing our server's throughput.
2. Thread Pooling: Leveraging existing threads from the pool to serve subsequent requests
In this approach, our server has a pre-allocated pool of threads to handle the client requests. When a request arrives, the server checks the pool for available threads and assigns a thread to the request.
This approach averts the overhead of creating and destroying a thread every time a client request arrives. However, in this approach, if all the threads in the pool are occupied, the client requests are queued and they may experience delays or timeouts based on the server capacity.
3. Hybrid approach: A mix of spawning new threads and pooling
In the hybrid approach, we leverage a mix of both approaches to optimize our servers' performance. Client requests are handled by a thread pool and if the threads are busy, as opposed to queuing the requests, the server spawns a new thread to handle them.
Server design involves tradeoffs and largely depends on the requirements. If we are focused on saving resources, we could queue the requests for the busy threads in the pool to process them later and not spawn new threads. And if we are concerned about the response latency and throughput, we should spawn new threads if and when the pool is occupied.
Also, thread pools are best fit where client requests are relatively short-lived and the threads are free sooner to handle the subsequent client requests. In contrast, if the client requests are long-lived, they may keep all the threads from the pool occupied, requiring us to spawn new threads to handle future requests. In this scenario, a multithreaded approach spawning new threads for every request would make more sense.
We need to keep the right balance between resource utilization and responsiveness. Understanding the server memory usage with the help of monitoring tools helps us make these decisions easier.
Besides these, there are two other approaches that enable us to make our server handle concurrent requests efficiently: Non-blocking asynchronous I/O and the event-driven approach.
4. Non-blocking asynchronous I/O
The above discussed multithreaded approaches are blocking in nature, where the main thread of execution is blocked to handle client requests. The non-blocking asynchronous I/O approach enables our server to handle the client requests in a non-blocking fashion.
Both blocking and non-blocking approaches have their use cases. The multithreaded blocking approach fits best for use cases where the request is CPU-intensive and threads can run in parallel, making the best use of multi-core processors. Also, we have more fine-grained control over thread creation, resource allocation and management.
In the non-blocking asynchronous approach, no thread of execution is blocked. Instead, the client requests are handled asynchronously and the server can continue processing other tasks while the client request is being processed. This allows the server to maximize resource utilization and responsiveness.
The non-blocking approach is fit for I/O-intensive requests/use cases, where a significant portion of the server's time is spent waiting for external resources, such as disk I/O or network communication. Requests that need to read from or write to the DB is one example of this.
5. Event-driven approach
The event-driven approach is closely related to the asynchronous, non-blocking approach, where the server responds to events and processes the requests with event loops and callbacks. The events are dispatched to appropriate handlers or callbacks once they are received and the server keeps running the event loop to handle the client requests in a non-blocking fashion.
The asynchronous non-blocking and the event-driven approach may look similar, but they differ in the implementation, programming models and how they handle concurrency and I/O operations.
In this post, I'll delve into the implementation of the first two approaches (spawning new threads and thread pooling) and the remaining approaches will be discussed in future posts.
Implementing a multithreaded server which spawns a new thread for handling every client request
Below is the code for a multithreaded TCP server that spawns a new thread to handle concurrent client requests. If you've gone through my previous post, you'll understand the code better.
public class TCPMultithreadedServer {
private static final Logger logger = LoggerFactory.getLogger(TCPMultithreadedServer.class);
public static void main(String[] args) {
int port = 6545;
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket(port);
logger.info("Multithreaded TCP server listening on port " + port);
while (true) {
Socket clientSocket = serverSocket.accept();
logger.info("Client connected: " + clientSocket.getInetAddress());
Thread clientThread = new Thread(new ClientHandler(clientSocket));
clientThread.start();
logger.info("New thread spawned to handle client request with ID: " + clientThread.getId());
}
} catch (IOException e) {
logger.error("Error: " + e.getMessage(), e);
} finally {
try {
if (serverSocket != null) {
serverSocket.close();
}
} catch (IOException e) {
logger.error("Error closing server socket: " + e.getMessage(), e);
}
}
}
private static class ClientHandler implements Runnable {
private final Socket clientSocket;
public ClientHandler(Socket clientSocket) {
this.clientSocket = clientSocket;
}
@Override
public void run() {
try (BufferedReader in = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true)) {
String message;
while ((message = in.readLine()) != null) {
logger.info("Message received from the client: " + message);
out.println("Server received: " + message); // Echo back to client
logger.info("Message sent back to the client: " + message);
}
} catch (IOException e) {
logger.error("Error handling client: " + e.getMessage(), e);
} finally {
try {
clientSocket.close();
logger.info("Client disconnected.");
} catch (IOException e) {
logger.error("Error closing client socket: " + e.getMessage(), e);
}
}
}
}
}The program creates a server socket object and binds it to port 6545. The socket listens for incoming client connections via the accept() method. I've discussed sockets, ports and client-server connections over TCP in my former post in detail. Please refer to it for more information.
I'll directly get to the part where our server spawns a new thread to process a client request.
Thread clientThread = new Thread(new ClientHandler(clientSocket));
clientThread.start();The above code creates a new thread to handle a client connection every time it receives a request. The ClientHandler object goes as an argument in the Thread class object as it holds the logic for processing the client request. It further takes in clientSocket as an argument.
The ClientHandler class implements the Runnable interface and implements the run() method.
In Java, the Runnable interface is used to define a task that can be executed concurrently by a thread. When a class implements the Runnable interface, it indicates that instances of that class can be executed as separate threads by passing them to a Thread object.
Every time a client request arrives, a new thread is spawned with the ClientHandler argument and the thread processes the run() method of the ClientHandler class. Each client request is processed in its own thread. This way, the clients don't have to wait while the server processes the current requests, all the requests are processed parallely and the throughput of our server is increased.
The ClientHandler class is implemented as a static nested class to encapsulate the logic for processing a client request. The isolation of the request processing logic makes our code more modular, organized and readable. We can further reuse it in different contexts when required.
In addition, having the thread processing logic in a separate class further enables us to manage the state of thread execution with class variables in addition to the behavior. This would not be possible if the code were enclosed in a function/method.
Adding static to the ClientHandler class makes it independent of the state of the outer class. This helps with thread safety.
I tested the server with a client program and here are the logs. You'll find the client program in my previous newsletter post as well.
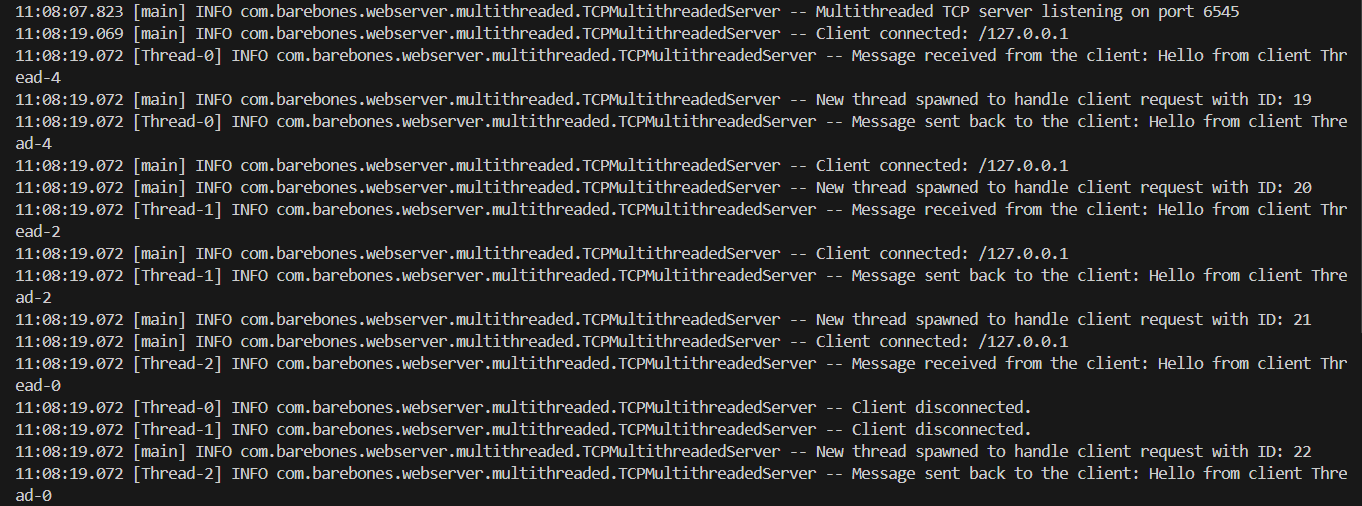
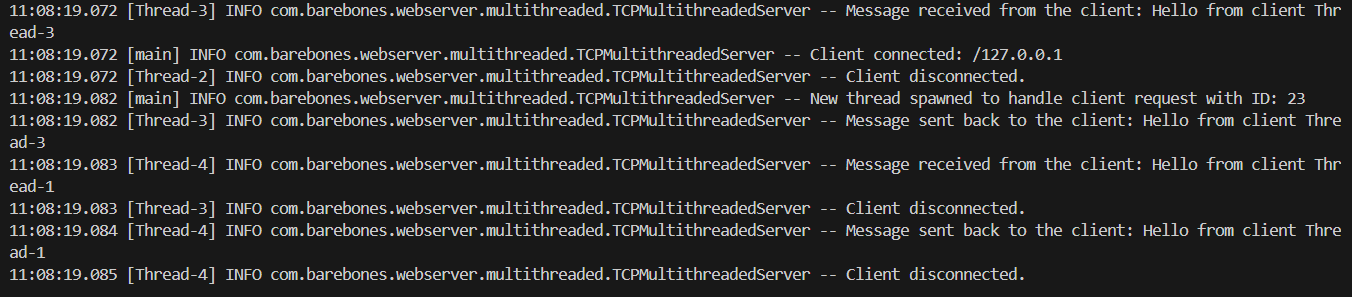
The server is hit by five concurrent requests that it handles by spawning a new thread for every request.
In Java, thread IDs are represented as long integers that we see in the logs. They are assigned sequentially as threads are created by the JVM.
Request response flow
When the main thread of our server receives a client request, it delegates the work to a newly spawned thread and returns to listen for other connections immediately. This allows our server to handle multiple client connections concurrently, which wasn't possible in our single-threaded TCP server.
The ability to handle multiple connections concurrently increases our server's responsiveness and throughput. This concurrent processing model is a common approach in servers that handle a large volume of concurrent client requests.
The accept() method is still blocking in nature. What if a large number of client requests arrive concurrently?
Even though our server handles client requests parallely in separate threads, the main thread that runs the accept() method is still blocking in nature.
The accept() method processes the client requests sequentially and then delegates them to individual threads. If a large number of requests arrive while the main thread is delegating work to a certain thread and is occupied, the requests are queued by the operating system.
The length of this queue, often referred to as the "backlog queue," determines the maximum number of pending connections that can be put into a waiting state for the server to accept them. The main thread handles them in the order they were received once it is free.
Moreover, it's essential to understand that the capacity of the server to handle concurrent connections is not solely determined by the operating system's queue. Factors such as system resources (CPU, memory), network bandwidth and the server's implementation (e.g., thread management, I/O handling, etc.) also play crucial roles in determining the server's scalability and performance.
Now, let's move on to the next implementation, where our server leverages a thread pool to handle concurrent client requests.
Implementing a multithreaded server that handles concurrent client requests with thread pooling
Below is the code for a multithreaded TCP server that maintains a thread pool to handle client requests as opposed to spawning a new thread every time.
public class TCPThreadPoolServer {
private static final int PORT = 6555;
private static final int THREAD_POOL_SIZE = 8;
private static final Logger logger = LoggerFactory.getLogger(TCPThreadPoolServer.class);
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(THREAD_POOL_SIZE);
try (ServerSocket serverSocket = new ServerSocket(PORT)) {
logger.info("Thread pool TCP server listening on port " + PORT);
while (true) {
Socket clientSocket = serverSocket.accept();
logger.info("Client connected: " + clientSocket.getInetAddress());
executor.execute(new ClientHandler(clientSocket));
logger.info("Client request submitted to thread pool for processing.");
}
} catch (IOException e) {
logger.error("Error: " + e.getMessage(), e);
} finally {
executor.shutdown();
}
}
private static class ClientHandler implements Runnable {
private Socket clientSocket;
public ClientHandler(Socket clientSocket) {
this.clientSocket = clientSocket;
}
@Override
public void run() {
try (BufferedReader in = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true)) {
String message;
while ((message = in.readLine()) != null) {
logger.info("Message received from the client: " + message);
out.println("Server received: " + message);
logger.info("Message sent back to the client: " + message);
}
} catch (IOException e) {
logger.error("Error handling client: " + e.getMessage(), e);
} finally {
try {
clientSocket.close();
logger.info("Client disconnected.");
} catch (IOException e) {
logger.error("Error closing client socket: " + e.getMessage(), e);
}
}
}
}
}This server program is pretty similar to the initial server program where we spawned a new thread for every client request. The primary difference is that here we are leveraging the Java Executor framework to create and manage a thread pool to handle client requests.
As opposed to explicitly spawning new threads on every client request, the Executor framework manages a pool of pre-allocated threads, cutting down on the thread creation overhead with every client request. The threads in the pool remain alive throughout the application's lifecycle.
ExecutorService executor = Executors.newFixedThreadPool(THREAD_POOL_SIZE);The above line of code creates a fixed-size thread pool where THREAD_POOL_SIZE is the number of threads in the pool.
executor.execute(new ClientHandler(clientSocket));The ClientHandler task is submitted to the thread pool for execution. This allows the thread pool to handle multiple client connections concurrently.
finally {
executor.shutdown();
}In the finally block, the executor framework shuts down the thread pool when the server is stopped for any resources to be released.
In the Java ecosystem, the Executor framework is largely used when dealing with threads as it provides better thread management in contrast to when explicitly handling the threads, plus other features as well. It comes in handy when working with threads.
With the Executor framework, we can create different types of thread pools, such as:
Fixed thread pool: Has a fixed number of threads
Cached thread pool: Can dynamically adjust the number of threads based on the workload. It spawns new threads when required.
Single thread pool: Maintains a single thread in the pool
Scheduled thread pool: Allows tasks to be scheduled for execution at a specified time or with a fixed delay.
Work stealing pool: This pool leverages the work-stealing algorithm to achieve high throughput and load balancing. Each thread in the pool has its own task queue and idle threads steal tasks from the queues of other threads to keep themselves busy. This pool is fit for parallel task processing use cases.
Queuing requests in an internal task queue with thread pooling
When all the threads in the pool are occupied and a client request arrives, the Executor framework queues that request to an internal task queue. When a thread becomes available, it picks up the request from the task queue. In addition, we can also set a task rejection policy based on our requirements.
Here are the server logs on running our thread pool program and sending concurrent requests to it.
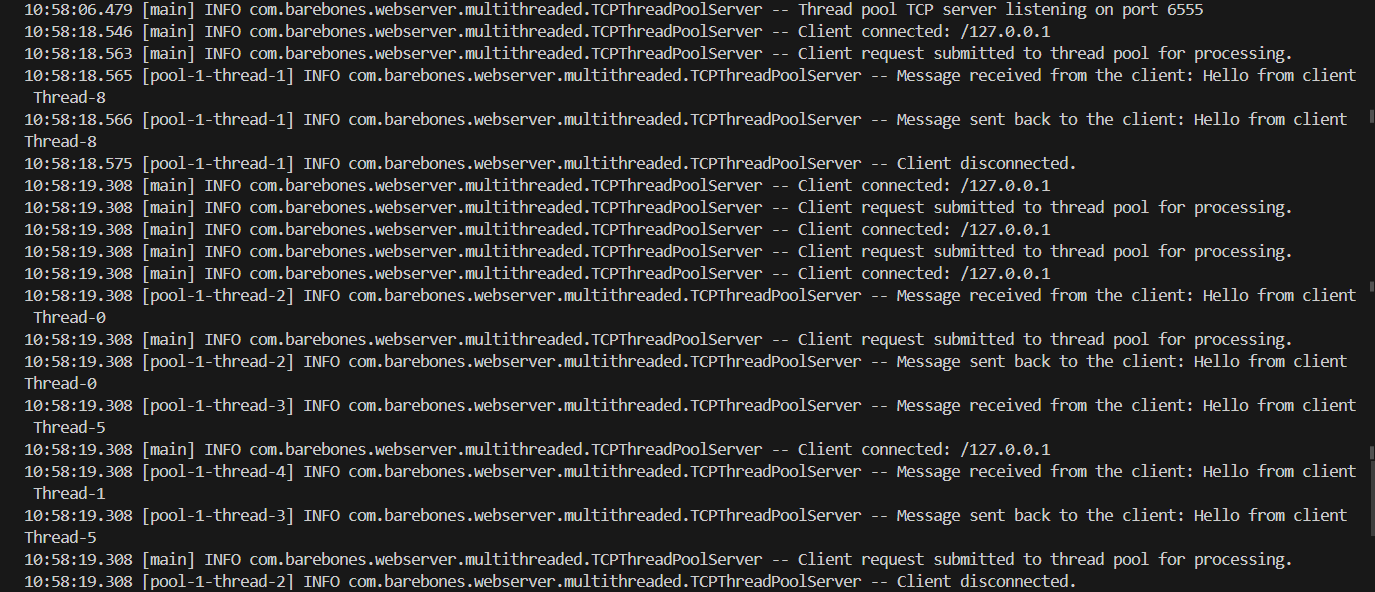


The server was hit by nine concurrent requests and each is handled by a thread from the pool.
A hybrid approach employing both thread pooling and spawning a new thread
Spawning a new thread to handle every client request and leveraging a thread pool to use existing threads to handle client requests are two specific implementations or approaches.
Modern servers leverage a mix of multiple approaches to achieve the desired behavior. Both thread pooling and thread spawning approaches have their pros and cons. I've discussed this a bit at the beginning of this post.
Modern servers strike a balance between resource utilization, responsiveness and scalability. Devs monitor the memory usage and tune the code continually for optimum performance and adapt to changing workload conditions. This may include studying the average number of concurrent requests, processing time per request, incoming request patterns like frequency of traffic spikes, system resource consumption such as CPU, memory, I/O capacity, scalability requirements, and so on.
Though the code in this post is in Java, you can learn to code distributed systems in the backend programming language of your choice with CodeCrafters (Affiliate).
CodeCrafters is a platform that helps us code distributed systems like Redis, Docker, Git, a DNS server, and more step-by-step from the bare bones in the programming language of our choice. With their hands-on courses, we not only gain an in-depth understanding of distributed systems and advanced system design concepts but can also compare our project with the community and then finally navigate the official source code to see how it’s done. It’s a headstart to becoming an OSS contributor.
You can use my unique link to get 40% off if you decide to make a purchase.
Both the system design and software architecture concepts and the distributed system fundamentals are a vital part of the system design interviews and coding distributed systems.
If you wish to master the fundamentals, check out my Zero to Software Architecture Proficiency learning path, comprising three courses that go through all the concepts starting from zero in an easy-to-understand language. The courses educate you, step by step, on the domain of software architecture, cloud infrastructure and distributed services design.
You can also check out several system design case studies and blog articles that I have written in this newsletter and my blog.
Well, this pretty much sums up the implementation of our TCP server, which can handle multiple clients concurrently. In my next post, I'll possibly delve into creating a node cluster and implementing a replicated state machine.
If you found this newsletter post helpful, consider sharing it with your friends for more reach.
If you are reading the web version of this post, consider subscribing to get my posts delivered to your inbox as soon as they are published.
You can get a 50% discount on my courses by sharing my posts with your network. Based on referrals, you can unlock course discounts. Check out the leaderboard page for details.

You can find me on LinkedIn & X and can chat with me on Substack chat as well. I'll see you in the next post. Until then, Chao!
Looking forward for the future posts about how to design a concurrent server. Especially how 4. Non-blocking asynchronous I/O and 5. Event-driven approach are used in real-world, and their implementation!
"The asynchronous non-blocking and the event-driven approach may look similar, but they differ in the implementation, programming models and how they handle concurrency and I/O operations."